معماری داده مقیاسپذیر
معماری داده مقیاسپذیر
راهنمای جامع طراحی معماری داده مقیاسپذیر برای سازمانهای متوسط
معماری داده مقیاسپذیر – مقدمه
معماری داده مقیاسپذیر – در عصر دیجیتال امروز، هر سازمانی به نوعی یک سازمان دادهمحور است. حتی شرکتهای متوسط با صدها هزار رکورد تراکنش، تعامل مشتری، دادههای جریان کلیک وبسایت یا دادهی حسگر، بهسرعت با چالشی روبهرو میشوند. در این مقاله سعی خواهیم کرد به سوال: چگونه زیرساخت دادهای طراحی کنیم که همزمان مقیاسپذیر، پایدار و مقرونبهصرفه باشد؟ پاسخ دهیم.
اغلب مدیران فناوری در این نقطه میپرسند: آیا واقعاً ما به معماری داده در سطح Enterprise نیاز داریم؟ پاسخ کوتاه این است: نه دقیقاً، اما به یک معماری داده مقیاسپذیر و هوشمندانه نیاز دارید که بتواند با رشد سازمان همراه شود بدون آنکه پیچیدگی یا هزینه را بهصورت تصاعدی بالا ببرد.

این مقاله بهصورت گامبهگام به شما کمک میکند تا چنین معماریای طراحی کنید، از شناسایی نیازها تا انتخاب ابزار و حتی استقرار در محیط ابری راهنمایی خواهد کرد. سعی شده است در هر بخش تکنولوژیهای متن باز جدید یا مبتنی بر ابر پیشنهاد گردد.
۱. درک مفهوم مقیاسپذیری در معماری داده
مقیاسپذیری یا Scalability فقط به معنی افزودن سرور یا افزایش ظرفیت ذخیرهسازی نیست، بلکه در دنیای تجزیهوتحلیل داده کسبوکار مقیاسپذیری یعنی:
- توانایی افزایش حجم داده بدون افت عملکرد
- پشتیبانی از افزایش کاربران و بار تحلیلی
- امکان افزودن منابع محاسباتی یا نودهای جدید بدون تغییر ساختار اصلی سیستم
- مقیاسپذیری تیم توسعهپذیری فرآیندها و گردشکار تیمهای داده
برای سازمانهای متوسط، مقیاسپذیری باید با هزینه بهینه و پیچیدگی کنترلشده همراه باشد. در غیر این صورت، معماری شما بهجای کمک، تبدیل به مانع رشد میشود.
۲. اجزای کلیدی معماری داده مدرن
معماری داده مدرن از چند لایه اصلی تشکیل میشود. هر لایه وظیفه مشخصی دارد اما باید طوری طراحی شود که بهصورت مستقل مقیاسپذیر باشد.
۲.۱. لایه منابع داده یا Data Sources
منابع داده میتوانند شامل موارد زیر باشند:
- دیتابیسهای تراکنشی (PostgreSQL, Oracle, MySQL)
- سرویسهای SaaS (مثل Salesforce یا HubSpot)
- فایلها و لاگها (CSV, JSON, Parquet)
- دادههای جریانی (Kafka, Kinesis)
طراحی خوب از همینجا شروع میشود باید مشخص گردد کدام دادهها حیاتی و هر منبع چقدر تغییرپذیر یا پویا است.

۲.۲. لایه استخراج و بارگذاری ETL / ELT
در سازمانهای متوسط، یکی از تصمیمات کلیدی انتخاب بین ابزارهای ETL و ELT است.
| Airbyte | Meltano | معیار |
| اتصالدهندههای آماده (Connectors) | مدیریت Pipeline داده و نسخهسازی | تمرکز اصلی |
| ELT محور | ETL محور | مدل کاری |
| سادگی در اتصال به منابع متعدد | انعطاف در پیکربندی و توسعه سفارشی | مزیت کلیدی |
| تیمهایی که بهدنبال راهحل سریع هستند | تیمهای مهندسی داده با کنترل بالا | مناسب برای |
در اکثر سناریوهای سازمانهای متوسط، استفاده از Airbyte برای جمعآوری دادهها و ترکیب dbt با Meltano برای تبدیل آنها ترکیب ایدهآلی است.
۲.۳. لایه ذخیرهسازی Data Lake / Data Warehouse
انتخاب بین Data Lake و Data Warehouse به نوع تحلیل شما بستگی دارد:
- اگر دادهها نیمهساختیافته یا بدون ساختار هستند استفاده از Data Lake و تکنولوژی S3, MinIO پیشنهاد میشود.
- اگر تحلیلهای ساختیافته و BI محور نیاز است، استفاده از Data Warehouse و تکنولوژیهای Snowflake, Redshift, BigQuery, ClickHouse پیشنهاد میگردد.
در سازمانهای متوسط معمولاً ترکیبی از هر دو استفاده میشود.
بهعنوان مثال:
- داده خام در S3 ذخیره میشود، منظور لایه Raw است.
- دادههای پردازششده در ClickHouse یا Redshift بارگذاری میشوند، منظور لایه Curated یا جمعآوری داده است
۲.۴. لایه پردازش و مدلسازی یا Transformation Layer
در این بخش ابزارهایی مانند dbt یا Spark برای تمیزسازی، مدلسازی و ساخت جداول تحلیلی استفاده میشوند.
اصول طراحی این لایه:
- Pipelineها باید ماژولار و قابل تست باشند.
- تغییرات Schema باید با نسخهسازی کنترل شوند.
- مدلها باید بر اساس دامنههای داده Data Domains طراحی شوند نه جداول فیزیکی.
۲.۵. لایه سرویسدهی و تحلیل یا Serving & BI Layer
دادههای نهایی باید در اختیار کاربران نهایی قرار گیرند از طریق:
- ابزارهای BI (Power BI, Tableau, Superset)
- APIها برای سرویسهای خارجی
- داشبوردهای تحلیلی داخلی
در این مرحله، تمرکز باید بر روی بهینهسازی Queryها و کنترل دسترسی دادهها باشد.
۳. اصول طراحی معماری داده مقیاسپذیر
طراحی معماری داده مقیاسپذیر، تنها انتخاب ابزار مناسب نیست؛ بلکه مجموعهای از اصول طراحی و تفکر سیستمی است که به شما اجازه میدهد داده را در هر مقیاسی از داده، از چند گیگابایت تا چند پتابایت با کیفیت و سرعت کنترل کنید. در این بخش، پنج اصل کلیدی معرفی میشود که زیربنای معماریهای موفق در سازمانهای متوسط هستند.
۳.۱. اصول طراحی ماژولار یاModular Design
معماری داده باید مانند سیستمهای نرمافزاری مدرن، قابلیت توسعه، جایگزینی و نگهداری مستقل اجزا را داشته باشد.
به زبان ساده، اگر شما تصمیم گرفتید ابزار ETL را از Meltano به Airbyte تغییر دهید، نباید مجبور شوید Pipelineها، مدلهای dbt یا حتی Data Warehouse را از نو بسازید.
نکات کلیدی در طراحی ماژولار:
- هر لایه از معماری که در این مقاله به آنها پرداختیم، شامل Ingestion، Storage، Transformation، Serving باید مرز مشخص و API واضح داشته باشد. مثلاً خروجی ابزار ETL همیشه در قالب فایلهای Parquet در S3 ذخیره شود تا مستقل از ابزار قابل خواندن باشد.
- از استانداردهای باز (Open Formats) مانند Parquet، Avro، Delta Lake استفاده شود تا وابستگی به یک فروشنده یا تامین کننده خاص یعنی Vendor Lock-in به حداقل برسد.
- بین تیمها قرارداد داده (Data Contract) تعریف شود تا هر بخش بداند چه نوع داده و در چه فرمت زمانی تحویل میدهد.
- از معماری Domain-driven الهام گرفته یعنی از Data Mesh استفاده کنید تا هر دامنه داده، مسئول Pipeline و مدلهای خودش باشد.
وقتی هر ماژول مرز مشخص داشته باشد، میتوان بدون اختلال کل سیستم، آن را جایگزین، بهینهسازی یا مقیاس دهی کرد.
۳.۲. خودکارسازی همه چیز یا Automation Everywhere
مقیاسپذیری واقعی زمانی اتفاق میافتد که انسانها از فرآیند حذف شوند. در معماری داده، هر کار تکراری باید قابل اتوماسیون باشد، این موضوع از ایجاد زیرساخت گرفته تا اجرای Pipeline و تست داده است.
سه سطح خودکارسازی:
- زیرساخت یا Infrastructure as Code: ابزارهایی مانند Terraform یا Pulumi اجازه میدهند تا تمام منابع ابری مانند S3، Redshift، IAM Roles و غیره را بهصورت نسخهپذیر و تکرارپذیر تعریف کنید.
- این کار نهتنها خطای انسانی را کاهش میدهد بلکه محیطهای مشابه Dev, Test, Prod را تضمین میکند.
- اجرای Pipeline یا Data Orchestration: ابزارهایی مثل Apache Airflow، Prefect یا Dagster زمانبندی، مانیتورینگ و وابستگی بین Pipelineها را مدیریت میکنند. بهجای اجرای دستی، هر تغییر یا بهروزرسانی باید از طریق DAGها Directed Acyclic Graphs کنترل شود.
- تست و اعتبارسنجی خودکار داده: با ابزارهایی مانند Great Expectations یا dbt tests میتوان کیفیت داده را قبل از بارگذاری بررسی کرد.
وقتی زیرساخت و فرآیندها خودکار باشیم، تیم داده میتواند روی تحلیل و نوآوری تمرکز کند نه نگهداری روزمره.
۳.۳. مشاهدهپذیری و مانیتورینگ Observability & Monitoring
شما نمیتوانید چیزی را که نمیبینید، مقیاس دهید. بنابراین یکی از اصول بنیادین در معماری داده مقیاسپذیر، قابلیت مشاهده Observability است. یعنی توانایی درک دقیق از وضعیت جریان داده، عملکرد Pipelineها، و سلامت سیستمها.
مؤلفههای اصلی Observability:
- Pipeline Monitoring: بررسی زمان اجرا، خطاها و میزان داده پردازششده در هر مرحله میباشد. ابزارهایی مانند Airflow UI، Prefect Cloud یا Dagster Cloud داشبوردهای عالی برای این منظور ارائه میدهند.
- System Metrics: مانیتورینگ مصرف CPU، حافظه و Storage با Prometheus + Grafana یا سرویسهای ابری مانند AWS CloudWatch قابل انجام است.
- Data Lineage: ردیابی مسیر داده از منبع تا داشبورد نهایی با ابزارهایی مثل Amundsen، OpenMetadata یا DataHub انجام میشود. این قابلیت برای دیباگ و ممیزی حیاتی است.
- Alerting: تعریف هشدارهای خودکار برای ناهنجاریها مانند افت حجم داده، افزایش تاخیر یا خطای پردازش.
با مانیتورینگ و مشاهدهپذیری کامل، تیم شما بهجای واکنش به خطاها، میتواند پیشگیرانه عمل کند.

۳.۴. کیفیت داده از طراحی (Data Quality by Design)
در معماریهای کوچک، معمولاً تست کیفیت داده در انتهای فرایند انجام میشود؛ اما در سیستمهای مقیاسپذیر، این رویکرد فاجعهبار است. اصل «Data Quality by Design» میگوید کنترل کیفیت باید در تمام مراحل جریان داده گنجانده شود.
چهار محور کیفیت داده:
- دقت Accuracy: داده باید با واقعیت بیرونی منطبق باشد. برای مثال، تاریخ تراکنش نباید از تاریخ سیستم جلوتر باشد. با تعریف قانونهای اعتبارسنجی در dbt یا Great Expectations قابل کنترل است.
- کامل بودن Completeness: هیچ فیلد حیاتی نباید مقدار Null یا Missing داشته باشد. این موضوع مهم در مرحله ETL باید بررسی شود.
- سازگاری Consistency: نام موجودیتها و واحدها در سیستمهای مختلف باید هماهنگ باشد. با Metadata و Schema Registry مدیریت میشود.
- بهروز بودن Timeliness:داده باید با فرکانس مناسب بهروزرسانی شود تا گزارشها دقیق باشند.
کیفیت بالا از ابتدا باعث میشود دادهها قابل اعتماد باشند و هزینه تصحیح خطاها در مراحل بعدی بهطور چشمگیر کاهش یابد.
۳.۵. امنیت و حاکمیت داده Security & Governance
داده در سازمانهای مدرن، یک دارایی استراتژیک است و داراییها نیاز به محافظت دارند. امنیت داده و حاکمیت داده باید از روز اول در طراحی معماری لحاظ شود، نه بهعنوان یک افزودنی در انتهای پروژه.
اصول امنیت و حاکمیت:
- کنترل دسترسی مبتنی بر نقش RBAC: کاربران فقط باید به دادههایی دسترسی داشته باشند که برای وظایفشان ضروری است. این سیاست میتواند در لایه BI، Data Warehouse یا حتی S3 اعمال شود.
- رمزنگاری Encryption: دادهها باید در حالت ذخیرهشده (at rest) و در حال انتقال (in transit) رمزنگاری شوند.
در AWS میتوان از KMS یا SSE-S3 استفاده کرد. - Masking و Tokenization: برای دادههای حساس مانند شماره ملی یا شماره کارت بانکی، از ماسکگذاری استفاده میشود تا تحلیلگران به داده بدون جزئیات شخصی دسترسی داشته باشند.
- Data Catalog و Metadata Management: با ابزارهایی مثل AWS Glue Data Catalog یا Databricks Unity Catalog، شناسنامهی دادهها و مالکیت آنها مشخص میشود. این کار از تکرار و آشفتگی در منابع داده جلوگیری میکند.
- Auditing و Compliance: ثبت رویدادهای دسترسی (Access Logs) برای پاسخ به الزامات قانونی مانند GDPR یا قوانین داخلی کشور ضروری است.
امنیت و حاکمیت قوی نهتنها از نشت داده جلوگیری میکند، بلکه اعتماد سازمان به داده را افزایش میدهد، عاملی حیاتی برای موفقیت پروژههای تحلیلی.
اصول پنجگانهی بالا یعنی ماژولار بودن، خودکارسازی، مشاهدهپذیری، کیفیت، امنیت مثل ستونهای یک ساختمان عمل میکنند.
اگر یکی از آنها سست باشد، معماری داده در مقیاس بزرگ ناپایدار میشود. به همین دلیل، توصیه میشود هر تصمیم فنی جدید در سازمان از انتخاب ابزار تا طراحی مدل با این پنج اصل سنجیده شود.
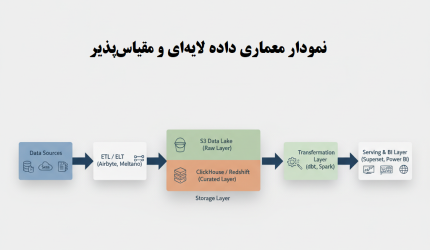
۴. معماری مرجع برای سازمانهای متوسط (الگوی پیشنهادی)
در این بخش، یک معماری نمونه ارائه میشود که قابل پیادهسازی روی AWS، GCP یا Azure است:
[Data Sources]
↓
[Airbyte / Meltano]
↓
[S3 Data Lake] ← Raw Layer
↓
[dbt / Spark] ← Transform Layer
↓
[ClickHouse / Redshift] ← Curated Layer
↓
[Superset / Power BI] ← BI Layer
ویژگیهای این معماری:
- هزینه متناسب با رشد داده یا Pay as you grow
- انعطاف برای اضافهکردن منابع جدید
- جداسازی لایهها برای نگهداری آسان
- پشتیبانی از Batch و Streaming
۵. چالشهای رایج و راهکارها
| راهحل | توضیح | چالش |
| Data Lifecycle Policy در S3 | داده خام زیاد و تکراری | افزایش هزینه ذخیرهسازی |
| Parallelization و Resource Scheduling | اجرای همزمان زیاد | کندی Pipelineها |
| Schema Registry و dbt Tests | تغییر در ساختار دادهها | ناسازگاری Schema |
| Lineage Tracking (Amundsen, OpenMetadata) | پیچیدگی سیستمها | نبود دید کامل روی جریان داده |
| IAM Policy دقیق و رمزنگاری در سطح Bucket/Table | دسترسیهای غیرمجاز | امنیت دادهها |
۶. گامهای عملی برای شروع طراحی معماری
۱. تحلیل نیازها و کاربران نهایی: مشخص شود چه کسی از داده استفاده میکند و با چه هدفی.
۲. مستندسازی منابع داده موجود: شناسایی و طبقهبندی منابع فعلی (Operational, Analytical, External).
۳. انتخاب معماری پایه Cloud-native یا Hybrid: برای سازمانهای متوسط، معماری Cloud-native مثل AWS S3 + Lambda + Redshift بهترین گزینه است.
۴. طراحی فرآیند جریان داده (Data Flow Diagram): نشان دهید داده از کجا وارد میشود و به کجا میرود.
۵. انتخاب ابزار مناسب برای هر لایه
- ETL: Airbyte / Meltano
- Transformation: dbt / Spark
- Storage: ClickHouse / Redshift
- Orchestration: Airflow / Prefect
- Monitoring: Prometheus / Grafana
۶. پیادهسازی نمونه اولیه (MVP)
ابتدا برای یک دامنهی محدود (مثلاً فروش یا کاربران) معماری را تست کنید.
۷. ارزیابی عملکرد و بهینهسازی
شاخصهایی مانند Throughput، Latency و Cost Efficiency را بسنجید.
۷. مطالعه موردی (Case Study)
یک شرکت خدمات مالی متوسط در تهران، با حدود ۲ ترابایت داده تراکنشی، تصمیم گرفت از یک سیستم سنتی Oracle به معماری داده مدرن مهاجرت کند. چالش اصلی، زمان طولانی تحلیل و نبود دید جامع از دادهها بود.
راهحل:
- انتقال داده خام به S3
- استفاده از Airbyte برای استخراج داده از Oracle و Salesforce
- پردازش با dbt و ذخیره در ClickHouse
- ساخت داشبورد در Superset
نتیجه:
- زمان تولید گزارش از ۴ ساعت به ۱۲ دقیقه کاهش یافت
- هزینه زیرساخت ۴۰٪ کاهش یافت
- دادهها در ۴ دامنهی مختلف (فروش، مشتری، تراکنش، محصول) بهصورت مجزا ولی قابل ترکیب نگهداری شدند
۸. توصیههای نهایی
- از کوچک شروع کنید، اما برای رشد طراحی کنید، هر سیستم دادهای باید قابلیت Scale Out داشته باشد.
- زیرساخت را با IaC کنترل کنید، Terraform یا CloudFormation مسیر مقیاسپذیری واقعی است.
- دادهها را دامنهمحور مدیریت کنید، اصل Data Mesh را در حد نیاز سازمان متوسط پیاده کنید.
- کیفیت داده مهمتر از حجم داده است.
معماری داده مقیاسپذیر – نتیجهگیری
طراحی یک معماری داده مقیاسپذیر برای سازمانهای متوسط، به معنی استفاده از ابزارهای گران یا پیچیده نیست. بلکه یعنی طراحی سیستمی که بتواند با رشد سازمان همراه شود بدون بازنویسی از صفر، با انتخاب هوشمندانه ابزارها، پیادهسازی تدریجی و تمرکز بر استانداردهای کیفیت و امنیت، میتوانید زیرساخت دادهای بسازید که نهتنها امروز پاسخگو باشد، بلکه فردا نیز قابل توسعه و پایدار باقی بماند.
تألیف: آقای مهندس رضا بهادری زاده
اگر در حال طراحی زیرساخت دادهای برای سازمان خود هستید و نمیدانید از کجا شروع کنید، فرم زیر را تکمیل بفرمائید:
نوشتن نظر